Scaling AI: Why Data Infrastructure is the Real Bottleneck
As enterprises shift from AI experimentation to production, optimizing data infrastructure is more critical for ROI than GPU count alone.
As enterprises shift from AI experimentation to production, optimizing data infrastructure is more critical for ROI than GPU count alone.
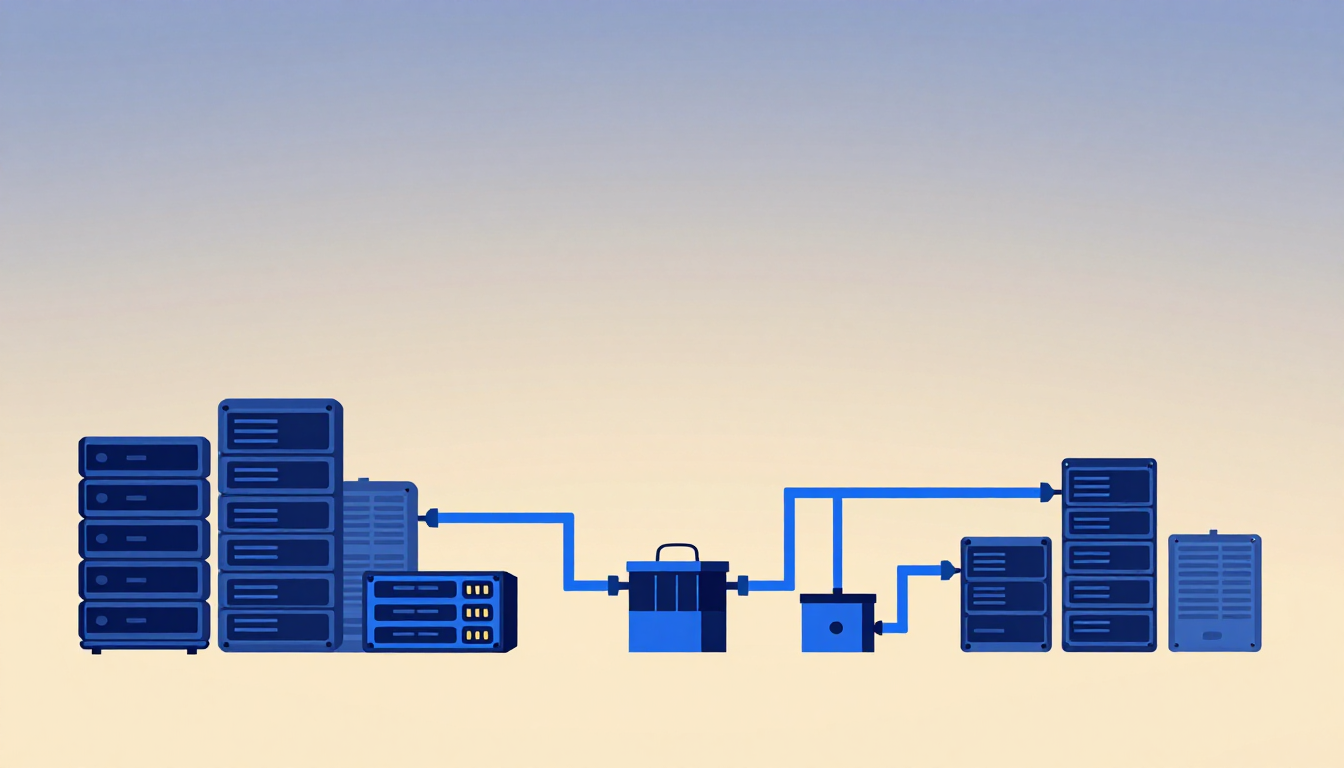
\n[Compute Nodes / GPUs] ---> [Application Delivery Controller (ADC)] ---> [S3 Object Storage]\n (TLS/TLS Offloading, Traffic steering,\n Policy enforcement, Load balancing)\n\n\nThe ADC offloads TLS termination, certificate management, traffic shaping, policy enforcement, and protocol-aware S3 processing. Freeing storage controllers from networking and cryptographic management allows storage platforms to dedicate their compute cycles exclusively to what they were optimized to perform: high-efficiency data I/O.\n\nFurthermore, this loose coupling introduces operational flexibility. IT teams can upgrade, migrate, or expand storage arrays and disk systems behind the ADC without altering a single line of code or network configuration on the client-facing AI application.\n +---------------------------------------------+\n | Application Delivery & Security (ADSP) |\n | |\n | [Traffic Eng] [Security] [Observability] |\n +---------------------------------------------+\n / | \\\n / | \\\n [On-Prem] [Public Clouds] [Edge]\n\n\n“AI broke the model of solving delivery and security as separate problems,” says Nirav Shah. “When data is moving constantly between storage, compute, and applications across hybrid multi-cloud environments, you need one platform that delivers and protects that traffic at the same time.”\n\nThis transition mirrors the evolution of the early web. Two decades ago, simple load balancers redirected HTTP traffic; as applications grew more complex, they evolved into application delivery controllers with security capabilities. AI is driving a similar architectural shift. With data moving continuously between distributed databases, inference engines, vector stores, and custom user interfaces, organizations must secure and optimize that entire traffic flow as a unified system.\n\nFor more on securing these evolving AI architectures, see From Passive Walls to Active Intelligence: Transforming Cybersecurity Infrastructure.![The Shift to Operationalization: The Reality of Production AI\n\nAs enterprises transition from the initial hype and experimentation phases of AI, the focus has shifted dramatically toward operationalization and return on investment (ROI). After an 18-month period defined by aggressive spending on GPUs, foundation models, and specialized AI tooling, organizations are now facing the reality that AI projects must deliver measurable business value to be sustainable.\n\nAccording to a 2025 IDC Spotlight report, organizations are rapidly moving away from isolated, one-off AI deployments and toward repeatable, scalable architectures designed to support sustained production workloads. As AI capabilities become deeply embedded across core business units—from credit scoring in financial services to diagnostic pipelines in healthcare—performance, security, reliability, and operational consistency are becoming just as critical as raw model innovation.\n\nThis new phase requires a move toward repeatable, scalable, and secure architectures. It's no longer just about having the latest Large Language Model (LLM); it's about embedding AI capabilities across the business with performance, reliability, and security that matches the scale of the enterprise. This realization is pushing CIOs to take a closer look at the foundational infrastructure that supports these distributed, data-intensive workloads.\n\n### Why Performance Falls Off a Cliff in Production\n\nConsider a scenario that has become all too common in enterprise deployments: A Tier-1 financial institution recently migrated from a successful AI fraud detection pilot to enterprise-scale inference. The test environment, handling synthetic datasets under controlled parameters, delivered sub-10ms response times with 500 requests per second. Production, however, settled into a plateau of 45-60ms latency and 15% GPU underutilization. \n\nRoot-cause analysis revealed the bottleneck wasn't model complexity, poor parameter tuning, or physical hardware limitations of the accelerators. It was network latency between object storage (S3) and GPU nodes during batch inference bursts. The GPUs were idle 70% of the time, starving for data to arrive [2].\n\nThis pattern repeats across industries. Healthcare organizations deploying AI-based diagnostic image processing, retail chains rolling out demand-forecasting engines, and manufacturers integrating predictive maintenance all see similar performance cliffs as they scale from proof-of-concept (PoC) to full production. The common denominator is a fundamental mismatch between the compute power deployed and the data fabric supporting it. When performance degrades, the immediate reaction of many tech leaders is to assume they need more compute: adding GPUs, expanding clusters, or trying other models. But in reality, the hardware isn't the problem. The GPUs aren't starving for compute; they are starving for data.\n\nSee also: LLM KV Cache Compression Techniques for related optimization strategies that extend beyond model-level improvements to data pipeline efficiency, or TensorWave's $350M Funding for how AI infrastructure startups are addressing these bottlenecks with AMD-based solutions](https://assets.probackend.com/bead70e0-d120-413c-b64a-e9e7daa60058?token=ast_7b9ee8975a4b187969d396286e3f9717c42f2331)